코사인 유사도를 이용한 사용자 기반 협업 필터링 추천시스템
이번 글에서는 Flask RESTful API를 구현합니다.
라이브러리 설치
pip install flask flask-restful mysql-connector-python
서버실행 flask run
상관계수를 이용한 아이템기반 협업 필터링 보기
상관계수를 이용한 영화 추천 시스템
추천 시스템을 구축하는 방법에는 여러 가지가 있지만,그 중 상관계수를 이용한 방법은 아이템 간의 유사도를 측정하여 추천하는 방식으로 많이 사용됩니다.이번 글에서는 상관계수를 이용한
maeilcoding.tistory.com
1. 사용자 기반 협업 필터링이란?
사용자 기반 협업 필터링(User-Based Collaborative Filtering)은 비슷한 취향을 가진 사용자들의 데이터를 활용하여 새로운 추천을 생성하는 방식입니다.
🔹 사용자 기반 협업 필터링의 원리
- 사용자의 영화 평점 데이터를 분석
- 사용자가 특정 영화에 몇 점을 줬는지를 분석하여, 사용자 간 취향의 유사도를 측정합니다.
- 비슷한 취향을 가진 사용자 그룹 찾기
- 예를 들어, A와 B 사용자가 대부분 비슷한 영화에 비슷한 평점을 줬다면, A와 B는 비슷한 취향을 가짐.
- 비슷한 취향을 가진 사용자가 높게 평가한 영화를 추천
- A가 아직 보지 않은 영화 중에서, B가 높게 평가한 영화를 A에게 추천합니다.
2. 코사인 유사도(Cosine Similarity)란?
코사인 유사도는 두 벡터 간의 각도를 비교하여 유사도를 측정하는 방법입니다.
- 값의 범위: -1 ~ 1
- 1에 가까울수록 유사한 패턴
- 0에 가까울수록 관계 없음
- -1에 가까울수록 반대 패턴
🔹 예제
사용자 A와 B가 영화에 대한 평점을 아래와 같이 매겼다고 가정해 봅니다:
사용자 영화1 영화2 영화3 영화4
| A | 3 | 1 | 5 | 3 |
| B | 5 | 4 | 0 | 1 |
| C | 5 | 4 | 1 | 2 |
| D | 2 | 2 | 3 | 4 |
이 두 벡터 간의 코사인 유사도를 계산하면, B와 C는 매우 비슷한 취향을 가진 사용자로 판단할 수 있습니다.
3. 사용자 기반 협업 필터링 코드 설명
🔹 Flask RESTful API 기반 영화 추천 시스템
이 코드는 Flask RESTful API를 활용하여 사용자에게 맞는 영화 추천 시스템을 구현하는 사용자 기반 협업 필터링 방식의 추천 알고리즘입니다.
1️⃣ 명세서 확인
추천영화 리스트 API 명세서
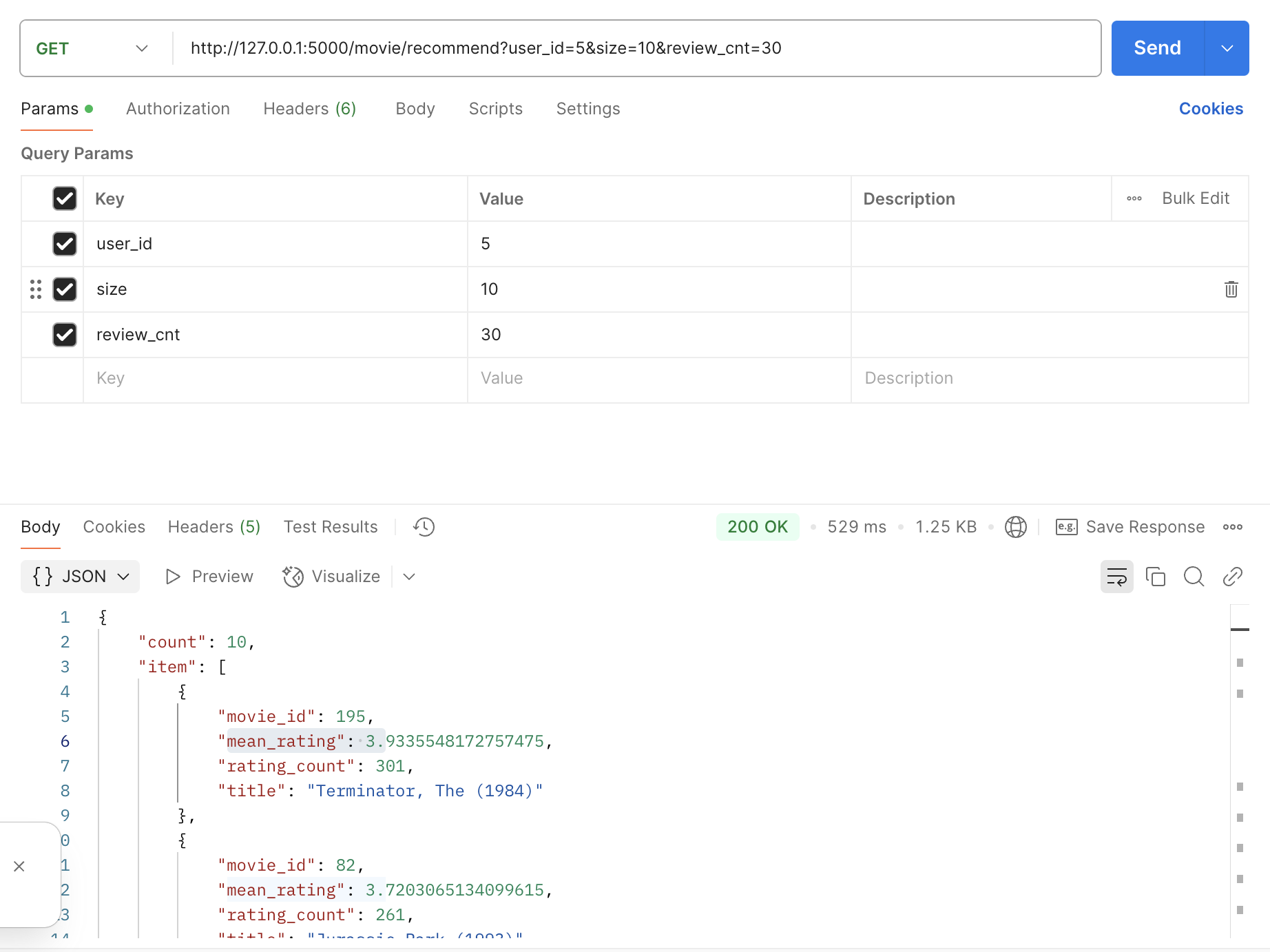
GET /
movie/recommend?user_id=4&size=10&review_cnt=30
* 유저아이디 4번, 데이터 10개씩, 리뷰개수 30개 이상인것으로
-Response 200 OK
{
"count":10,
"items":[{"movie_id":103, "average_rating":4.3,"rating_count":54, "title":"Toystory"},
{},{},{},{},{},{},{},{},{}
]
}
사용자가 GET 요청을 보낼 때, (movie/recommend?user_id=4&size=10&review_cnt=30)
해당 user_id의 영화 추천 목록을 리뷰개수 30개 이상의 영화 중 10개를 반환하는 API입니다.
user_id=request.args.get('user_id') # 사용자 ID 가져오기
size=request.args.get('size') # 추천할 영화 개수
review_cnt=request.args.get('review_cnt') # 최소 리뷰 개수 설정
connection=get_connection() # MySQL 연결
- user_id: 추천을 받을 사용자의 ID
- size: 몇 개의 영화를 추천받을 것인지
- review_cnt: 최소한 몇 개의 리뷰가 달린 영화만 포함할 것인지
2️⃣ Flask 서버 관련 핵심 모듈 설정 및 영화 및 리뷰 데이터 가져오기
query = """
select r.movie_id ,r.user_id ,r.rating
from review r ;
"""
review_df=pd.read_sql_query(query,connection)
- review_df: 사용자 ID, 영화 ID, 평점 데이터가 들어 있는 리뷰 데이터
query = """
SELECT id as movie_id, title
FROM movie m ;
"""
movie_df=pd.read_sql_query(query,connection)
- movie_df: 영화 ID와 제목이 들어 있는 데이터
pandas 라이브러리를 이용해 DB에 쿼리를 보내 데이터를 받아올 수 있습니다.
DB에 연결하기 위해서는
config.py 설정, mysql_connection.py 설정이 필요합니다.
config.py
#mysql_connection.py
import mysql.connector
import os
from config import DevConfig, ProdConfig
def get_connection():
#로컬에서 실행하는지, prod에서 실행하는지에 따라 Config클래스에서 host를 다르게 설정
if os.environ.get('FLASK_ENV') == 'prod':
config = ProdConfig
else:
config = DevConfig # prod가 아니면 개발용으로 설정된다.
connection=mysql.connector.connect(
host= config.DB_Host,
port= config.DB_PORT,
database= config.DATABASE,
user= config.DB_USER,
password= config.DB_PASS
) #db에 연결하는 코드
return connection
#app.py, config.py, mysql_connection.py를 통해 데이터베이스에 연결하는 코드를 작성했다. (기본)
mysql_connection.py
#config.py
#자바에서는 yml 파일로 설정을 관리하지만 파이썬에서는 클래스로 관리한다.
class Config:
DATABASE = 'DB이름'
DB_USER = '유저아이디'
DB_PASS = '비밀번호'
# 데이터베이스, 유저, 패스워드를 DevConfig, ProdConfig에 상속시켜준다.
class DevConfig(Config):
#개발용 (로컬 DB 연결)
DB_Host = 'localhost'
DB_PORT = 3307
class ProdConfig(Config):
#배포용 (DB에 직접 연결)
DB_Host = '데이터베이스 호스트'
DB_PORT = 3306
app.py
from flask import Flask
from flask_restful import Api
from resource.recommend import RecommendResource
app=Flask(__name__)
api=Api(app)
#경로와 리소스를 연결한다.
api.add_resource( RecommendResource , "/movie/recommend")
if __name__ == '__main__':
app.run()
Java의 Spring Framework에서는 @RestController 또는 @Controller를 사용하여 HTTP 요청을 처리하는 반면,
Python에서는 Flask-RESTful의 Resource 클래스를 활용해 RESTful API 엔드포인트를 구현합니다.
resource 폴더를 만들어 관리합시다.
resource
from flask_restful import Resource
from flask import request
import pandas as pd
from mysql_connection import get_connection
from sklearn.metrics.pairwise import cosine_similarity
class RecommendResource(Resource): #Resource 클래스를 상속받아쓰는 RecommendResource 클래스
def get(self):
user_id=request.args.get('user_id') #사용자 아이디를 받아온다.
user_id=int(user_id)
size=request.args.get('size')
size=int(size) #str으로 오기때문에 int로 바꿔준다.
review_cnt=request.args.get('review_cnt')
review_cnt=int(review_cnt)
connection=get_connection() #mysql_connection.py의 get_connection 함수를 호출
→ MySQL DB에서 영화와 리뷰 데이터를 가져오기 위해 데이터베이스에 연결합니다.
3️⃣ 특정 사용자의 평점 데이터 가져오기
query = f"""
select *
from review r
where r.user_id = {user_id};
"""
user_rating=pd.read_sql_query(query,connection)
- 현재 user_id가 평가한 영화 데이터를 가져옵니다.
if user_rating.shape[0]==0:
popular_movies =self.get_popular_movie(review_df,movie_df)
return {"count":popular_movies.shape[0], "item":popular_movies.to_dict('records')}, 200
- 해당 사용자의 평가 데이터가 없는 경우(새로운 사용자)
→ 인기 있는 영화를 추천해줍니다.
4️⃣ 리뷰 개수가 적은 영화 필터링
movie_list=review_df['movie_id'].value_counts()
valid_movie_list=movie_list[movie_list>=review_cnt].index
filtered_review_df=review_df.loc[review_df['movie_id'].isin(valid_movie_list),]
- 리뷰가 너무 적은 영화는 변별력이 떨어지므로 제외
- review_cnt 이상의 리뷰가 달린 영화만 포함
5️⃣ 영화-사용자 평점 행렬 생성
movie_user_matrix=filtered_review_df.pivot_table(index='movie_id', columns='user_id', values='rating')
movie_user_matrix=movie_user_matrix.fillna(0)
- 행(index) = 영화 ID, 열(columns) = 사용자 ID, 값(values) = 평점
- NaN 값은 0으로 채웁니다.
- 아이템기반이면 index : movie_id, columns ; user_id 🍌
- 사용자기반이면 index: user_id, columns : movie_id 🍌
6️⃣ 코사인 유사도 계산
item_similarity=cosine_similarity(movie_user_matrix)
item_similarity_df=pd.DataFrame(
index=movie_user_matrix.index,
columns=movie_user_matrix.index,
data=item_similarity
)
- cosine_similarity()를 사용해 영화 간 유사도를 계산
- item_similarity_df: movie_id를 기준으로 영화 간 유사도를 나타내는 데이터프레임
7️⃣ 사용자에게 추천할 영화 찾기
watched_movies=user_rating.loc[user_rating['movie_id'].isin(valid_movie_list) ,]
if watched_movies.shape[0] ==0:
popular_movies=self.get_popular_movie(review_df,movie_df)
return {"count":popular_movies.shape[0], "item":popular_movies.to_dict('records')}, 200
- 사용자가 본 영화 중 리뷰 개수가 30개 이상인 영화만 선택
- 만약 유효한 영화가 없다면 → 인기 영화 추천
8️⃣추천 점수 계산
recommendation_df=pd.DataFrame(index=movie_user_matrix.index)
recommendation_df['similarity_score'] = 0
- 추천 점수를 저장할 데이터프레임 생성
for movie_id in watched_movies['movie_id'].tolist():
rating_df = user_rating.loc[user_rating['movie_id']==movie_id, ]['rating'].iloc[0]
recommendation_df['similarity_score']+=item_similarity_df.loc[movie_id,]*rating_df
- 사용자가 본 영화와 유사한 영화에 가중치를 부여하여 추천 점수 계산
9️⃣ 추천 리스트 정리
movie_stats=filtered_review_df.groupby('movie_id')['rating'].agg(['mean', 'count']).reset_index()
recommendation_df.reset_index(inplace=True)
recommendation_df=pd.merge(recommendation_df,movie_stats,on='movie_id',how='left')
recommendation_df=recommendation_df.loc[~recommendation_df['movie_id'].isin(watched_movies['movie_id'].tolist()),]
top_movies=recommendation_df.sort_values('similarity_score',ascending=False).head(size)
top_movies=pd.merge(top_movies,movie_df,on='movie_id')
top_movies=top_movies.drop('similarity_score',axis=1)
- 평균 평점과 리뷰 개수를 추가하여 영화의 신뢰도를 높임
- 사용자가 이미 본 영화는 제외
- 추천 점수가 높은 순서대로 상위 size개 영화 선택
4. 결과: JSON 응답 반환
return {"count":top_movies.shape[0], "item":top_movies.to_dict('records')},200
→ 사용자에게 맞춤형 추천 리스트를 JSON 형식으로 반환
✅ 결론
✔ 사용자 기반 협업 필터링을 이용하여 유사한 취향을 가진 사용자들의 데이터를 활용해 추천
✔ 코사인 유사도를 통해 영화 간 유사도를 계산하여 추천 정확도 향상
✔ 사용자가 본 영화가 없거나 리뷰가 적다면 인기 영화 추천
이제 실행하면 사용자의 취향을 반영한 맞춤형 영화 추천이 가능합니다! 🚀🎯