
데이터 분석 개요 🧮
서울시 5대 범죄(강간, 강도, 살인, 절도, 폭력) 데이터를 기반으로, 각 구별 범죄 발생과 검거율 데이터를 분석하고 시각화합니다.
이 글에서는 데이터 처리, 변환, 그리고 원하는 데이터 분석을 얻기 위한 주요 기술과 실습 내용을 공유합니다. 📊✨
데이터 로드와 초기 처리 🗂️
숫자 데이터 처리
CSV 파일에서 쉼표(,)로 구분된 숫자를 바로 정수(int)로 변환하려면 pandas의 read_csv 함수에서 thousands=',' 옵션을 사용합니다.
이를 통해 숫자 데이터를 정수형으로 처리할 수 있습니다. ✅
import pandas as pd
df = pd.read_csv('crime_in_Seoul.csv', encoding='euc-kr', thousands=',')
아래 방법으로도 인트형 변환 가능합니다.
df['절도 발생']=df['절도 발생'].str.replace(',','').astype(int)
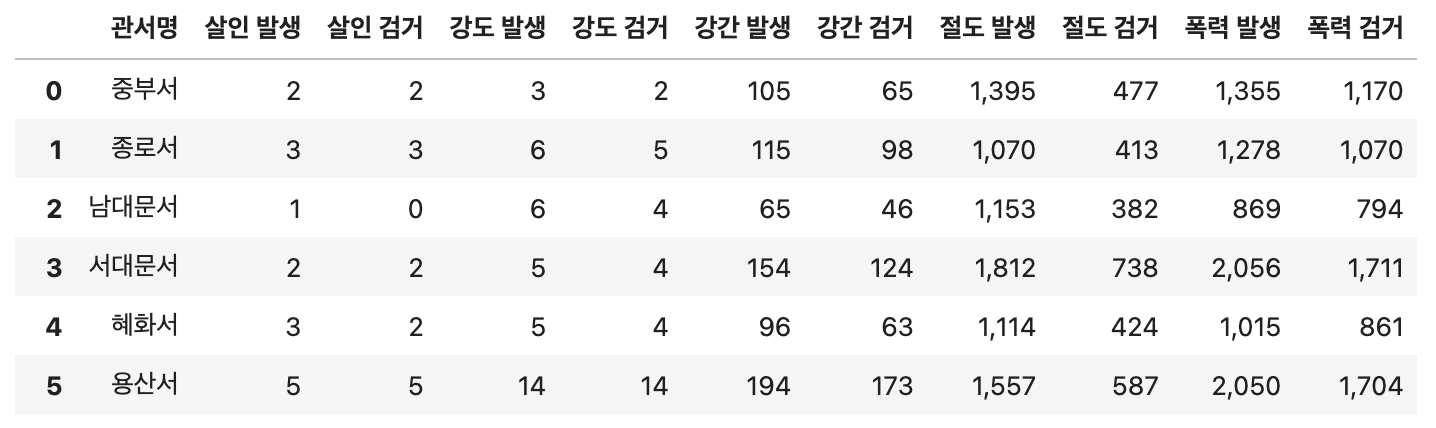
관서명이 아닌 지역구별로 컬럼을 보여주기위해 구글API를 이용하겠습니다.
구글맵 API 활용: 주소 데이터 처리 📍
지역구별 데이터로 통합하기 위해, 경찰서의 주소에서 구를 추출해야 합니다. 이를 위해 Google Maps API를 활용할 수 있습니다. Python 라이브러리 googlemaps를 사용하면 간단히 주소 데이터를 처리할 수 있습니다. 🗺️
Google Maps API 사용 방법
1. 구글 API에서 Geocoding API 신청
https://console.cloud.google.com/
Google 클라우드 플랫폼
로그인 Google 클라우드 플랫폼으로 이동
accounts.google.com
Google Cloud Console에서 프로젝트 생성하는 법
2. 구글맵 라이브러리 설치:
! pip install googlemaps
import googlemaps
gmaps_key = 구글 서비스키 # 자신의 key를 사용합니다.
gmaps = googlemaps.Client(key=gmaps_key)
gmaps.geocode('서울중부경찰서', language='ko')
gmaps.geocode 실행시 서울중부경찰서의 주소데이터를 리스트로 가져옵니다.
결과출력 :
[{'address_components': [{'long_name': '67',
'short_name': '67',
'types': ['premise']},
{'long_name': '퇴계로',
'short_name': '퇴계로',
'types': ['political', 'sublocality', 'sublocality_level_4']},
{'long_name': '중구',
'short_name': '중구',
'types': ['political', 'sublocality', 'sublocality_level_1']},
{'long_name': '서울특별시',
'short_name': '서울특별시',
'types': ['administrative_area_level_1', 'political']},
{'long_name': '대한민국',
'short_name': 'KR',
'types': ['country', 'political']},
{'long_name': '04529', 'short_name': '04529', 'types': ['postal_code']}],
'formatted_address': '대한민국 서울특별시 중구 퇴계로 67',
'geometry': {'location': {'lat': 37.55990389999999, 'lng': 126.9794911},
'location_type': 'ROOFTOP',
'viewport': {'northeast': {'lat': 37.5612528802915,
'lng': 126.9808400802915},
'southwest': {'lat': 37.5585549197085, 'lng': 126.9781421197085}}},
'place_id': 'ChIJc-9q5uSifDURLhQmr5wkXmc',
'plus_code': {'compound_code': 'HX5H+XQ 대한민국 서울특별시',
'global_code': '8Q98HX5H+XQ'},
'types': ['establishment', 'point_of_interest']}]
여기서 필요한 부분은 'formatted_address': '대한민국 서울특별시 중구 퇴계로 67'의 '중구' 입니다.
result=gmaps.geocode('서울중부경찰서', language='ko')
result[0]['formatted_address']
#출력
'대한민국 서울특별시 중구 퇴계로 67'
result[0]['formatted_address'].split()[2]
#출력
'중구'
station_addreess 에 저장된 주소에서, 구만 추출하여 컬럼 만들기
관서명만 가지고는 구글 주소로 찾을 수 없습니다.
단어 앞에 '서울', 맨 끝 글자인 '서'를 떼어내고 '경찰서'를 붙여 이름을 다시 만듭니다.
df_name='서울'+df['관서명'].str[0:-2+1]+'경찰서'
#출력결과:
0 서울중부경찰서
1 서울종로경찰서
2 서울남대문경찰서
3 서울서대문경찰서
4 서울혜화경찰서
...
준비 된 df_name으로 주소를 반환하겠습니다.
# 함수를 하나 만든다.
def get_address(name):
result=gmaps.geocode(name, language='ko')
return result[0]['formatted_address']
#df_name을 get_address()로 싹 실행해라
df_address=df_name.apply(get_address)
#전체 주소 중 구만 추출하기 위해 스플릿해서 컬럼저장
df['구별']=df_address.str.split().str[2]
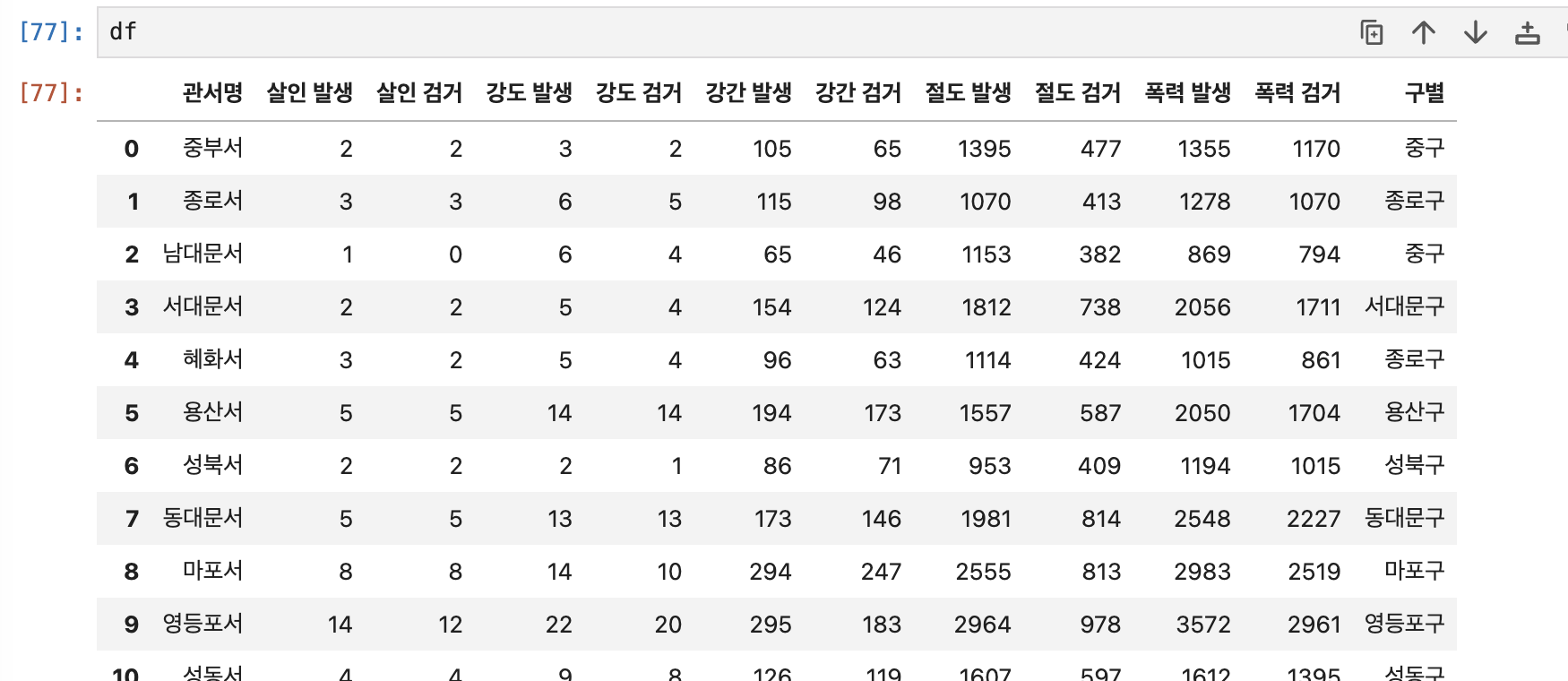
하나의 구에 경찰서가 2개 이상인 곳도 있네요.
구 내의 범죄는 합치도록 하겠습니다.
데이터 변환: 피벗 테이블 🔄
피벗 테이블 생성
피벗테이블이란?
pivot_table은 판다스(Pandas) 라이브러리의 중요한 기능 중 하나로, 데이터를 재구성하고 요약하는 데 매우 유용한 기능입니다.
- 데이터 재구성: 세로 데이터를 가로 데이터로 변환
- 데이터 요약: 지정된 기준에 따라 데이터 집계 가능
- 멀티인덱스 생성: 복잡한 데이터 구조 표현 가능
pd.pivot_table(df, values='Score', index=['Subject'], columns=['Name'], aggfunc='mean', fill_value=0)기본 구성
- values: 집계할 데이터 열
- index: 행 인덱스로 사용할 열
- columns: 열 인덱스로 사용할 열
- aggfunc: 데이터 집계 함수 (기본값: 'mean')
💡 TIP: values 옵션에는 숫자형 컬럼만 사용할 수 있습니다.
문자열 데이터가 포함되지 않은 경우 values를 생략해도 무방합니다.
다양한 집계 함수 활용
- 기본값: 평균 (mean) ➡️ 범죄 데이터를 비교할 때 적합.
- 합계: 'sum' ➡️ 전체 데이터를 집계할 때 적합.
- 최소값: 'min' ➡️ 최저 수치를 확인할 때 유용.
#관서명은 이제 필요없다. 삭제
df.drop('관서명',axis=1,inplace=True)
pd.pivot_table(df,index=['구별'],aggfunc='sum')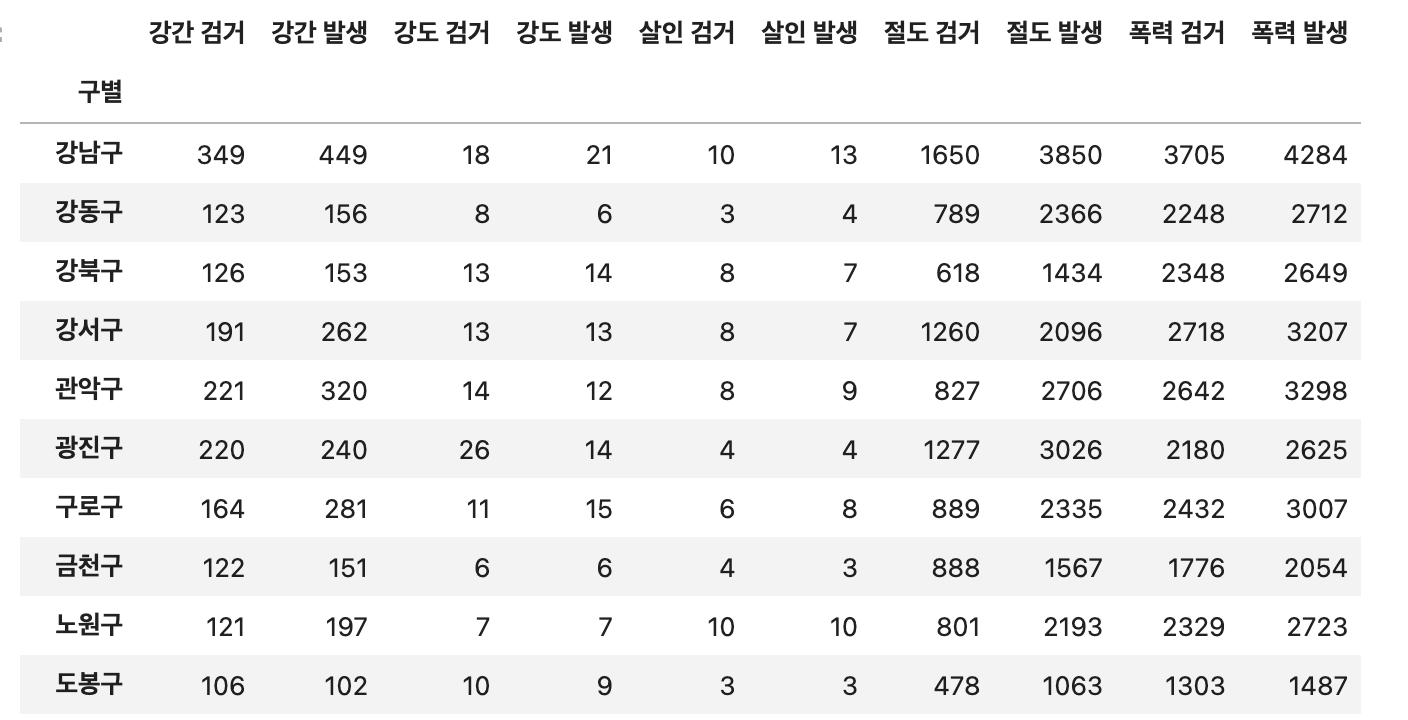
검거율 계산 및 정규화 🧮⚖️
검거율 계산
5대 범죄별 검거율을 계산한 뒤, 기존 데이터프레임에 새로운 컬럼으로 추가합니다.
df['강간검거율'] = (df['강간검거'] / df['강간발생']) * 100
df['강도검거율'] = (df['강도검거'] / df['강도발생']) * 100
# 다른 범죄들도 동일한 방식으로 계산
정규화(Normalization)
사람은 퍼센티지로 비교를 하지만, 컴퓨터는 정규화 혹은 표준화된 데이터로 비교가 가능합니다.
정규화는 서로 다른 범위를 가진 데이터를 동일한 스케일로 변환하는 과정입니다. 이를 통해 데이터 비교가 더 쉬워집니다. ⚙️
from sklearn.preprocessing import MinMaxScaler, StandardScaler
#싸이킥런 #전처리 = 정규화,표준화 처리
#강간, 강도, 살인, 절도, 폭력 을 노멀라이징
#1. 정규화 MinMaxScaler
scaler = MinMaxScaler()
scaler.fit_transform(df.loc[ : ,'강간':'폭력'])
df.loc[ : ,'강간':'폭력'])=scaler.fit_transform(df.loc[ : ,'강간':'폭력']
#2. 표준화 StandardScaler()
scaler2=StandardScaler()
scaler2.fit_transform(df.loc[ : ,'강간':'폭력'])

⚡ 정규화 vs 표준화:
- 정규화(Normalization): 데이터를 [0, 1] 범위로 변환. ➡️ 상대적 비교를 위해 유용.
- 표준화(Standardization): 데이터 평균이 0, 표준편차가 1이 되도록 변환. ➡️ 통계 분석에 적합.
데이터 시각화: Seaborn Heatmap 🖼️
히트맵을 활용한 데이터 시각화
Seaborn의 heatmap을 사용하면 데이터의 패턴과 관계를 직관적으로 확인할 수 있습니다. 🎨
5대범죄검거율의 값을 모두 더하고 검거라는 컬럼을 만들어넣기.
df['검거']=df.loc[ : , '강간검거율':'폭력검거율'].sum(axis=1)
import seaborn as sb
import matplotlib.pyplot as plt
df1=df.sort_values('검거',ascending=False).loc[ : ,'강간검거율':'폭력검거율']
plt.figure(figsize=(10,8))
sb.heatmap(data=df1,cmap='RdPu',annot=True,linewidths=0.8,fmt='.1f') #소수점 뒤로 1자리만
plt.show()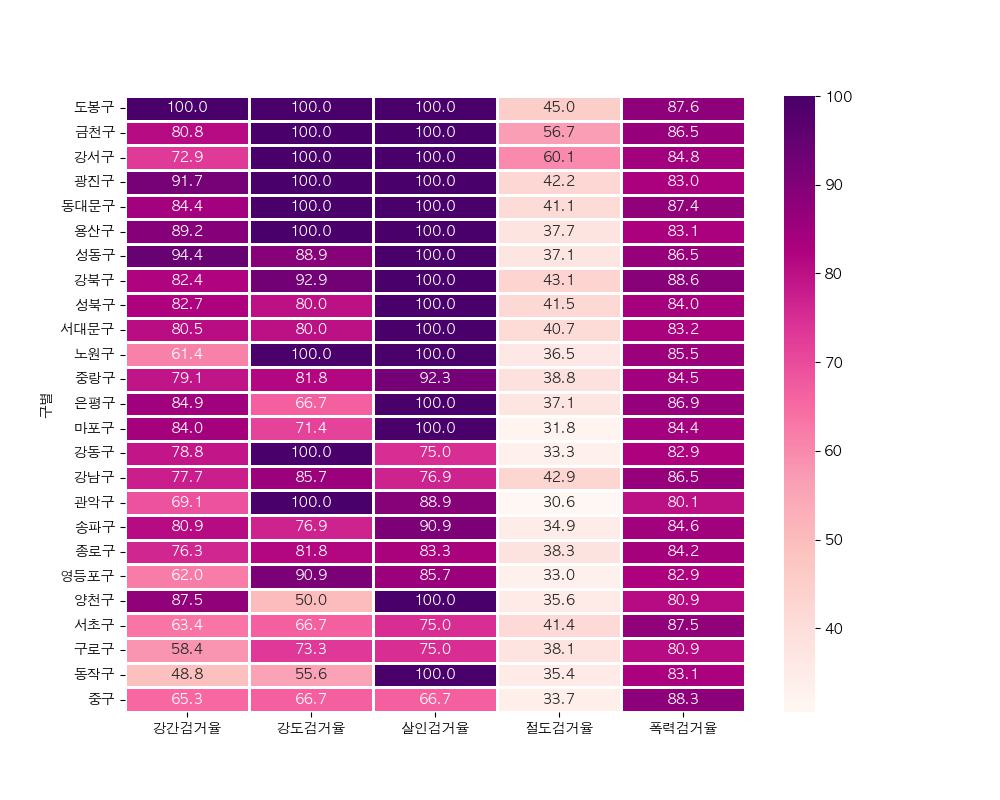
색이 진할수록 검거율이 높다.
결론: 데이터 분석의 가치 💡
이 프로젝트에서는 범죄 데이터를 다양한 관점에서 분석하고 시각화했습니다. 주요 학습 내용은 다음과 같습니다:
- Google Maps API를 활용한 구별 데이터 통합. 🌐
- 피벗 테이블과 집계 함수로 데이터 변환 및 요약. 📊
- 검거율 계산 및 정규화로 데이터 간 비교 가능성 향상. 📏
- Seaborn 히트맵을 통한 데이터 시각화. 🎨



