1. 🔧 머신러닝이란?
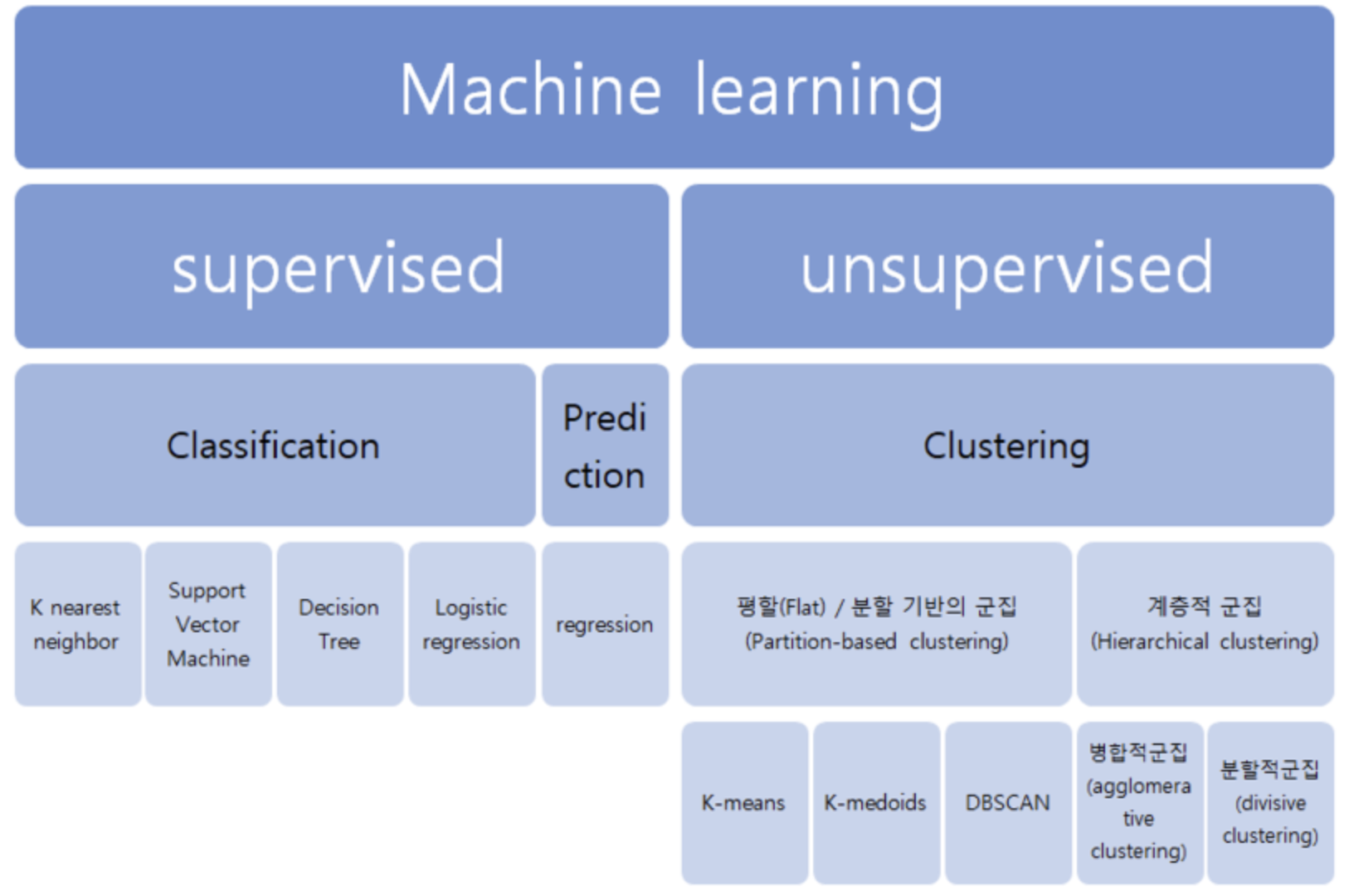
머신러닝은 데이터를 기반으로 학습하고, 학습한 내용을 바탕으로 새로운 데이터를 예측하거나 결정을 내리는 인공지능(AI)의 한 분야입니다. 머신러닝은 문제의 특성과 데이터에 따라 크게 두 가지 주요 유형으로 나뉩니다:
🔬 1.1 지도 학습(Supervised Learning)
- 정의: 입력 데이터와 그에 대한 정답(레이블)이 주어진 상태에서 모델을 학습시키는 방식.
- 종류:
- 회귀(Regression): 연속적인 값을 예측. 예: 집값, 주가 예측
- 분류(Classification): 데이터를 특정 클래스로 분류. 예: 스팸 이메일 필터링, 질병 진단.
특징 회귀(Regression) 분류(Classification)
| 예측 값 | 연속적인 숫자 (예: 가격, 온도) | 이산적인 값 (예: 스팸/정상) |
| 목표 | 입력과 출력 사이 관계 모델링 | 데이터를 클래스에 할당 |
머신러닝 분류(Classification) 모델 만들기: 구매 예측 모델 예시
머신러닝을 활용하여 "구매할 것인가, 안 할 것인가"를 예측하는 모델을 만드는 방법을 단계별로 설명해 보겠습니다. 1. 필요한 라이브러리 설치 및 불러오기먼저 머신러닝 작업을 위해 필
maeilcoding.tistory.com
선형 회귀 (Linear Regression):
- 입력 변수와 출력 변수 간의 선형 관계를 가정합니다.
- 예: "집 크기"와 "집값" 간의 관계.
- 모델 공식: y=mx+by = mx + b (기울기 mm과 절편 bb로 설명)
머신러닝 Linear Regression 모델 만들기: 연봉 예측 모델 예시
🔍 회귀(Regression) 분석과 실제 서비스화 🌟🔹Regression 란?회귀는 결과값(타겟)이 연속적인 수치로 표현되는 문제를 해결하기 위한 머신러닝 방법입니다.예를 들어, 직원의 경력을 바탕으로 연
maeilcoding.tistory.com
🔍 1.2 비지도 학습(Unsupervised Learning)
- 정의: 정답(레이블)이 없는 데이터에서 패턴이나 구조를 학습.
- 종류:
- 군집화(Clustering): 유사한 데이터를 그룹화. 예: 고객 세분화.
- 차원 축소(Dimensionality Reduction): 고차원 데이터를 효율적으로 표현. 예: 데이터 시각화.
⚙️ 2. 머신러닝 모델링 과정
머신러닝 모델링은 문제를 해결하기 위해 데이터를 기반으로 모델을 설계하고 학습시키는 과정입니다.
2.1 모델링 단계
- 문제 정의: 해결하고자 하는 문제를 명확히 설정.
- 데이터 준비:
- 데이터 수집 및 전처리 (결측값 처리, 이상치 제거 등).
- 데이터 분리 (훈련 데이터, 검증 데이터, 테스트 데이터).
- 모델 선택: 문제 유형(회귀, 분류 등)에 적합한 알고리즘 선택.
- 모델 학습: 훈련 데이터를 이용해 모델을 학습시킴.
- 모델 평가: 테스트 데이터를 사용해 성능 평가.
- 모델 튜닝: 하이퍼파라미터 조정 등으로 모델 성능 개선.
- 모델 배포: 학습된 모델을 서비스에 통합하여 실제 사용.
🔢 3. 모델 성능 평가
모델 성능 평가는 모델이 얼마나 정확하게 문제를 해결하는지를 측정하는 과정입니다. 문제 유형에 따라 평가 지표가 달라집니다.
3.1 회귀 모델 평가 지표
- MSE (Mean Squared Error): 예측값과 실제값의 차이의 제곱 평균.
- RMSE (Root Mean Squared Error): MSE의 제곱근.
- MAE (Mean Absolute Error): 예측값과 실제값의 차이의 절댓값 평균.
- R² (R-squared): 데이터의 분산을 얼마나 잘 설명하는지.
3.2 분류 모델 평가 지표
- 정확도 (Accuracy): 전체 데이터 중 올바르게 예측한 비율.
- 정밀도 (Precision): 양성으로 예측한 것 중 실제 양성 비율.
- 재현율 (Recall): 실제 양성 중에서 올바르게 예측한 비율.
- F1 스코어: 정밀도와 재현율의 조화 평균.
- ROC-AUC: 다양한 임계값에서의 모델 성능을 시각적으로 표현.
문제 유형 주요 평가 지표
| 회귀 | MSE, RMSE, MAE, R² |
| 분류 | 정확도, 정밀도, 재현율, F1 스코어, AUC |
⚠️ 4. 머신러닝 모델 적용 시 주의사항
4.1 데이터 품질
- 정확성: 데이터 오류나 노이즈 제거.
- 완전성: 필요한 데이터가 모두 포함되어 있는지 확인.
- 일관성: 데이터 형식과 값의 일관성 유지.
4.2 데이터 편향
- 학습 데이터의 다양성을 확보해 모델이 편향되지 않도록 주의.
4.3 과적합(Overfitting)과 과소적합(Underfitting)

- 과적합: 학습 데이터에만 최적화되어 새로운 데이터에 성능이 저하되는 현상. 해결 방법: 규제화, 드롭아웃.
- 과소적합: 데이터의 패턴을 충분히 학습하지 못하는 현상. 해결 방법: 더 복잡한 모델 사용.
4.4 특징 엔지니어링(Feature Engineering)
- 데이터에서 유용한 특징을 추출하고 변환하여 모델 성능을 향상.
4.5 해석 가능성
- 모델의 예측 결과를 이해하고 설명할 수 있도록 해석 가능성을 확보.
💡 5. 머신러닝 활용 사례
- 의료: 질병 진단, 환자 데이터 분석.
- 금융: 신용 점수 평가, 사기 탐지.
- 소비자 분석: 고객 행동 예측, 추천 시스템.
- 산업: 예측 유지 보수, 공정 최적화.
🎯 6. 결론
머신러닝은 데이터 기반의 문제 해결을 가능하게 하며, 다양한 분야에서 활용되고 있습니다. 성공적인 머신러닝 모델을 개발하려면 적절한 알고리즘 선택, 데이터 품질 확보, 성능 평가, 그리고 주의사항을 철저히 고려해야 합니다.


