1.🤖 SVM이란?
Support Vector Machine(SVM)은 머신러닝의 지도 학습(Supervised Learning) 알고리즘 중 하나로, 주로 분류(Classification) 문제에서 강력한 성능을 발휘합니다.
SVM의 기본 개념은 데이터를 선형 혹은 비선형적으로 분류하는 **최적의 결정 경계(Decision Boundary)**를 찾는 것입니다. 이 결정 경계를 **초평면(Hyperplane)**이라고 부르며, SVM은 이 초평면을 데이터의 마진을 최대화하는 방식으로 찾습니다.
🍏 실생활 예제: 사과와 오렌지 구분하기 🍊

사과와 오렌지를 구분하는 문제를 생각해봅시다. 우리는 크기, 색깔, 무게 등의 특징을 이용해 이 둘을 구별할 수 있습니다.
- 만약 크기와 색깔을 기준으로 한다면, 2차원 공간에서 데이터를 표현할 수 있습니다.

- 이제 사과와 오렌지가 분류될 수 있도록 가장 적절한 선(결정 경계)을 찾는 것이 SVM의 역할입니다.

- SVM은 가장 가까운 사과와 오렌지 데이터 포인트(서포트 벡터)를 이용해 최대 마진을 가지는 선을 찾아 최적의 분류를 수행합니다.
2. 📏 마진(Margin)과 서포트 벡터(Support Vector)
SVM에서는 데이터 포인트들이 분류되는 선(결정 경계)과 가장 가까운 데이터 포인트들의 거리를 **마진(Margin)**이라고 합니다. 마진을 최대화하는 것이 SVM의 핵심 목표입니다.
- 🎯 Support Vector: 결정 경계에 가장 가까운 데이터 포인트들로, 이 데이터 포인트들이 결정 경계를 형성하는 데 중요한 역할을 합니다.
- 🔍 Hard Margin vs. Soft Margin:
- Hard Margin: 데이터가 완벽하게 선형 분리될 경우, 가장 큰 마진을 가지는 결정 경계를 찾음.
- Soft Margin: 데이터가 완벽히 분리되지 않는 경우, 약간의 오차를 허용하며 분류 성능을 극대화.
3. 🔄 선형과 비선형 SVM
(1) 🏛 선형 SVM

선형적으로 구분 가능한 데이터에 대해 SVM은 가장 큰 마진을 가지는 직선을 찾아 분류합니다.
이는 sklearn.svm.SVC(kernel='linear')을 사용하여 구현할 수 있습니다.
(2) 🌀 비선형 SVM과 커널 트릭(Kernel Trick)
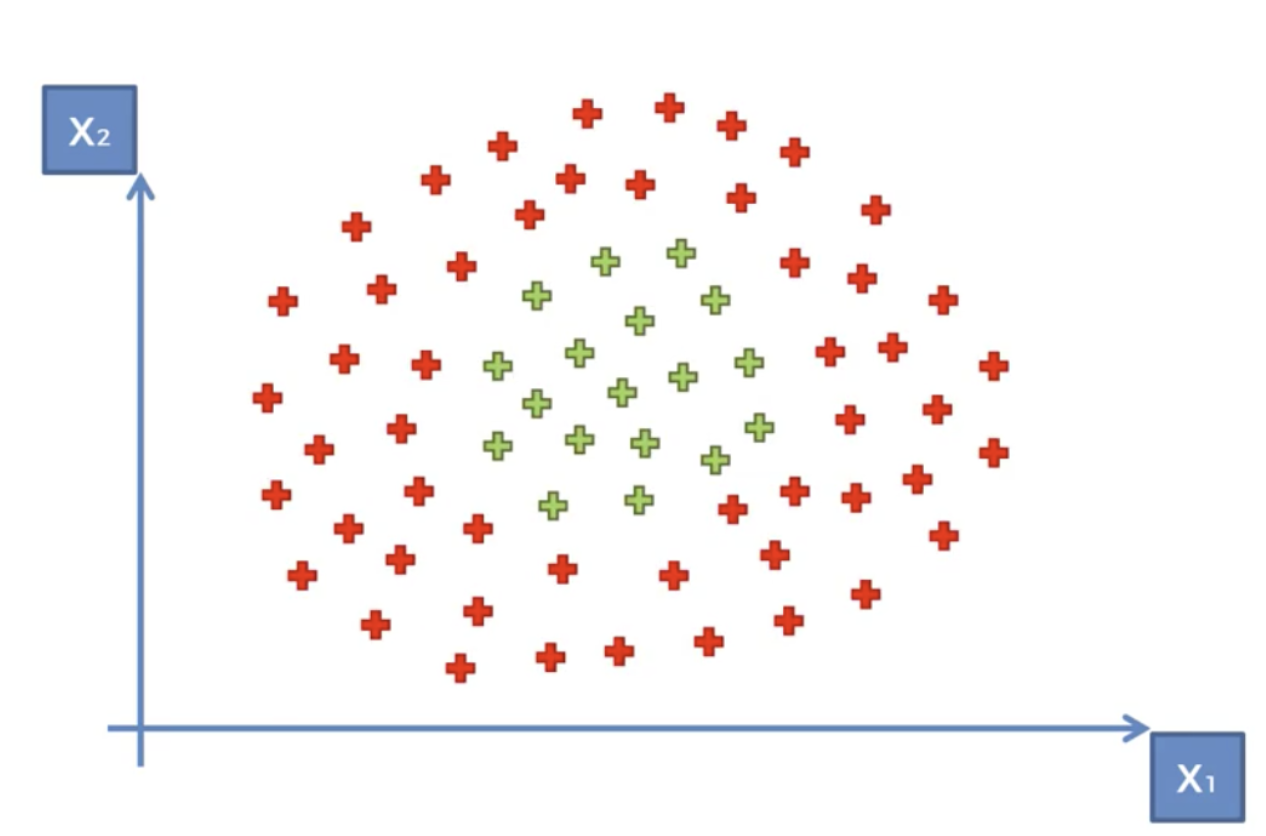
실제 데이터는 대부분 선형적으로 분리되지 않기 때문에, SVM은 커널 트릭(Kernel Trick)을 사용하여 데이터를 더 높은 차원의 공간으로 변환합니다.
- ⚡ 커널의 종류 및 활용 예제
- 📏 선형 커널 (Linear Kernel): kernel='linear'
- 사용 사례: 데이터가 명확한 선형 패턴을 따를 때 적합함 (예: 직선으로 구분 가능한 금융 사기 탐지)
- 🔢 다항식 커널 (Polynomial Kernel): kernel='poly'
- 사용 사례: 데이터가 곡선 형태의 결정 경계를 따를 때 유용함 (예: 손글씨 숫자 인식)
- 🌊 RBF 커널 (Radial Basis Function Kernel): kernel='rbf'
- 사용 사례: 데이터가 복잡한 비선형 패턴을 보일 때 유용함 (예: 질병 진단에서 여러 생체 신호를 기반으로 분류)
- 🌀 시그모이드 커널 (Sigmoid Kernel): kernel='sigmoid'
- 사용 사례: 뉴럴 네트워크의 활성화 함수처럼 작용하며, 데이터가 특정 임계점을 중심으로 구분될 때 적합 (예: 감정 분석에서 긍정/부정 판단)
- 📏 선형 커널 (Linear Kernel): kernel='linear'
4. 📝 SVM 구현 예제 (Python)
아래는 scikit-learn을 사용하여 SVM을 구현하는 기본 코드입니다.
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.metrics import confusion_matrix, accuracy_score
# 데이터 로드
df = pd.read_csv('../data/Social_Network_Ads.csv')
#nan 확인
df.isna().sum()
#Xy 나눔
y=df['Purchased']
X=df.loc[ : , 'Age':'EstimatedSalary']
#문자열체크
X.info()
#피쳐스케일링 regression모델들과 다르게 별도의 스케일링 작업이 필요하다.
scaler_X=StandardScaler()
X=scaler_X.fit_transform(X)
#학습용 테스트용 준비
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# SVM 모델 생성 및 학습
classifier=SVC(kernel='rbf') # 커널 트릭에 맞춰 파라미터 입력
classifier.fit(X_train,y_train)
# 예측 및 평가
y_pred=classifier.predict(X_test)
confusion_matrix(y_test,y_pred)
accuracy_score(y_test,y_pred)
5. ⚖️ SVM의 장점과 단점
✅ 장점
- 🎯 고차원 데이터에서 효과적으로 동작
- 🔄 커널 트릭을 사용하여 복잡한 패턴을 학습할 수 있음
- 📊 비교적 적은 데이터에서도 우수한 성능을 보임
❌ 단점
- 🏋️ 데이터의 크기가 커지면 계산량이 많아짐
- 🛠 최적의 커널과 파라미터를 찾는 과정이 필요
- 🎭 노이즈가 많거나 중첩된 데이터에서는 성능이 떨어질 수 있음
6. 🏁 결론
SVM은 강력한 분류 알고리즘으로, 특히 작은 데이터셋에서 우수한 성능을 발휘합니다. 커널 트릭을 통해 복잡한 분류 문제를 해결할 수 있으며, 다양한 머신러닝 응용 분야에서 사용됩니다. 하지만 데이터가 많을 경우 속도 저하와 최적의 하이퍼파라미터 선택이 필요하다는 점을 고려해야 합니다.
✨ SVM을 활용하여 다양한 머신러닝 프로젝트에서 최적의 분류 성능을 달성해 보세요! 🚀



